The Microscopic
The Microscopic was a public video mapping installation exhibited at the Art Gallery of Ontario in March 2025. I showcased a real-time generative AI animation driven by an interactive
multimodal system. This project explored generative animations assisted by human motion tracking and a generative trained model.
Image conditioning is a powerful concept I just started to understand by the time I was presenting this project. Instead of relying on pure random generation, I explored ways how we can feed our
diffusion model with given prompts to have control over what output we would likely get.
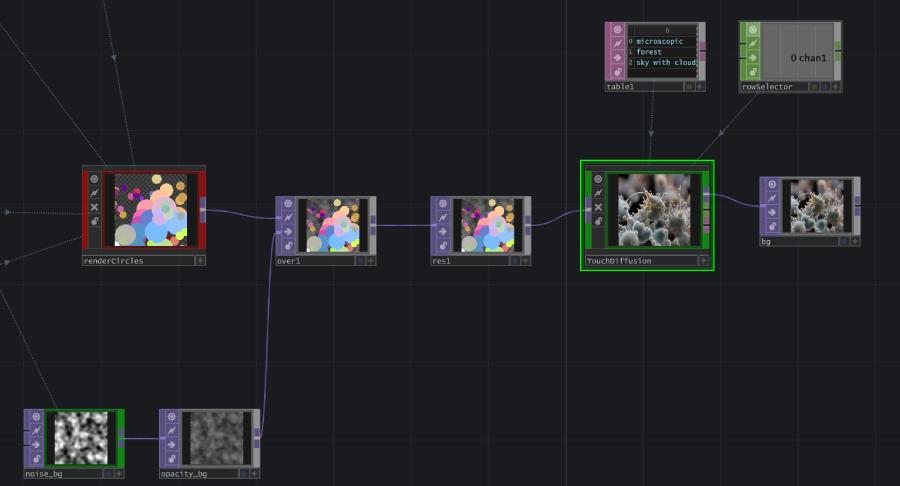
In this case, I created a particle animation composed of high-contrast circular forms. These visuals acted as a strong reference for the model, maintaining coherence while allowing variation through the noise map. Think of it like the model saying: "I can be creative, but this shape looks like it matters, so I’ll preserve it."
In this case, I created a particle animation composed of high-contrast circular forms. These visuals acted as a strong reference for the model, maintaining coherence while allowing variation through the noise map. Think of it like the model saying: "I can be creative, but this shape looks like it matters, so I’ll preserve it."

This project used three layers to shape how images were generated and transformed in real time.
- First, a real-time AI image model generated visuals based on text prompts. In simple terms, the words and ideas behind the prompt guided what the AI created.
- Second, a pre-made animation acted as a base structure. This animation worked like a skeleton or blueprint that the AI followed while generating new imagery on top of it.
- Finally, the system responded to hand gestures. Through a set of programmed rules, visitors could use their hands to partially or fully change the animation as it was happening.
Because this work ran live in the gallery, performance and responsiveness were critical. To achieve this, the system was converted into an optimized inference model using ONNX.
This allowed the computer vision and AI processes to run with hardware acceleration, significantly reducing latency. As a result, the experience became smoother and more responsive, improving performance from an average of 8 frames per second to a stable 16–20 frames per second during the exhibition.
This allowed the computer vision and AI processes to run with hardware acceleration, significantly reducing latency. As a result, the experience became smoother and more responsive, improving performance from an average of 8 frames per second to a stable 16–20 frames per second during the exhibition.
This type of projects is the perfect scenario to build my way up as a pipeline developer who understand some of these cutting-edge AI vision models as a extension of my current available toolkit for creative
workflows. "AI" didn't create my artwork but it helped me to shape the visual effects for the animations.
How do we build credibility beyond this AI hype? ...I can think on a couple of questions:
How do we build credibility beyond this AI hype? ...I can think on a couple of questions:
- Does this tool meaningfully reduce time-intensive or repetitive tasks?
- Is this AI-based architecture scalable and modular enough to integrate into my creative pipeline?